Video Codec — An Introduction
A walkthrough of how a standard video codec works, covering motion estimation, DCT, quantization, entropy coding, and decoding.
Video codecs are the backbone of modern media streaming, videoconferencing, and storage. Standards like H.264 [1] and H.265/HEVC [2] achieve impressive compression ratios by exploiting both spatial and temporal redundancy in video. This post walks through the core encoder–decoder pipeline shared by most traditional video codecs.
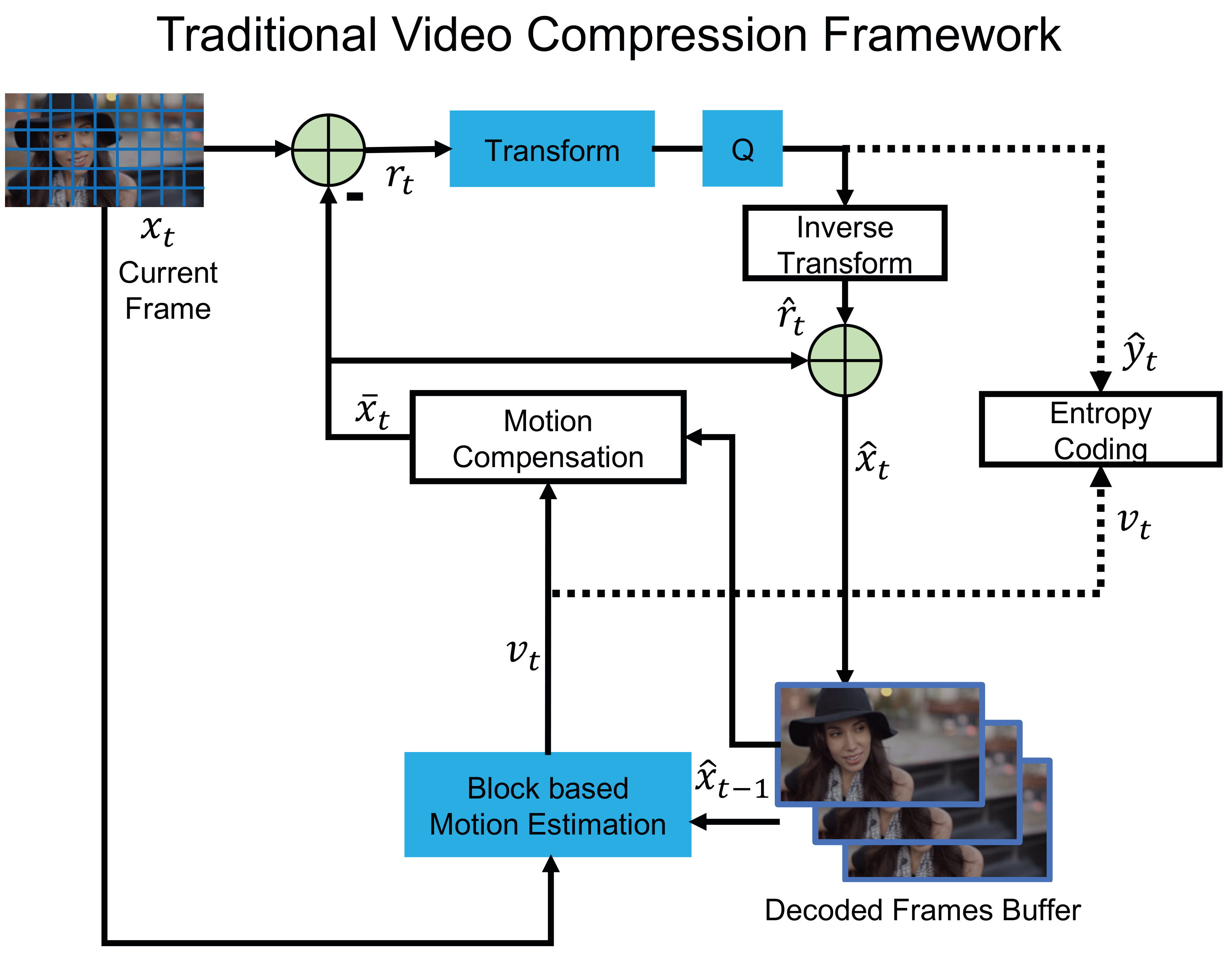
Encoder
Step 1: Motion Estimation
The encoder estimates the motion between the current frame $x_t$ and the previous reconstructed frame $x_{t-1}$ stored in the Decoded Picture Buffer (DPB). This produces a motion vector $v_t$ for each macro-block, describing how regions of the image have shifted between frames.
Step 2: Motion Compensation
Using $v_t$, the encoder warps the previous frame to produce a predicted image $\bar{x}_t$. The difference between the current and predicted frame — the residual — is then computed as:
\[r_t = x_t - \bar{x}_t\]Because consecutive frames in a video tend to look similar, $r_t$ is typically small and sparse, making it much cheaper to encode than the full frame.
Step 3: Transform and Quantization
The residual $r_t$ is transformed into the frequency domain using the Discrete Cosine Transform (DCT) [4]. DCT concentrates most of the signal energy into a small number of low-frequency coefficients, and since the human visual system is far less sensitive to high-frequency detail, those components can be aggressively discarded.
The transformed coefficients are then quantized to produce $\hat{y}_t$. Quantization introduces a controlled loss of precision — it is the primary source of compression loss in traditional codecs, and the quantization parameter (QP) directly controls the quality–bitrate trade-off. A key side benefit of DCT is that it reduces the variance of the data, which allows the subsequent entropy encoder to achieve better compression.
Step 4: Inverse Transform
To prepare the DPB for encoding the next frame, the encoder reconstructs an approximation of the current frame. The quantized coefficients $\hat{y}_t$ are passed through the inverse DCT to recover the reconstructed residual $\hat{r}_t$, which is then added back to the predicted image:
\[\hat{x}_t = \bar{x}_t + \hat{r}_t\]This reconstructed frame $\hat{x}_t$ is stored in the DPB. Note that this step mirrors exactly what the decoder will do, ensuring encoder and decoder stay in sync.
Step 5: Entropy Coding
Finally, the quantized residual $\hat{y}_t$ and the motion vectors $v_t$ are losslessly compressed using an entropy coder (e.g., CABAC in H.264/H.265) and packed into the output bitstream.
Decoder
The decoder is structurally simpler than the encoder — it runs a subset of the same operations.
Step 1: Entropy Decoding
The decoder parses the incoming bitstream to recover the quantized residual $\hat{y}_t$ and the motion vectors $v_t$.
Step 2: Inverse Transform
The residual $\hat{y}_t$ is passed through the inverse DCT to convert it back to pixel-domain residual $\hat{r}_t$.
Step 3: Motion Compensation
The decoder maintains its own DPB. Using the motion vectors $v_t$, it warps the previously decoded frame $\hat{x}_{t-1}$ to predict the current frame $\bar{x}_t$.
Step 4: Frame Reconstruction
The predicted frame $\bar{x}_t$ and the residual $\hat{r}_t$ are combined to reconstruct the final output frame:
\[\hat{x}_t = \bar{x}_t + \hat{r}_t\]This $\hat{x}_t$ is stored in the decoder’s DPB and displayed to the user.
References
-
[1]Wiegand, T. et al. 2003. Overview of the H.264/AVC Video Coding Standard. IEEE Transactions on Circuits and Systems for Video Technology. 13, 7 (2003), 560–576.
-
[2]Sullivan, G.J. et al. 2012. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Transactions on Circuits and Systems for Video Technology. 22, 12 (2012), 1649–1668.
-
[3]Lu, G. et al. 2019. DVC: An End-to-end Deep Video Compression Framework.
-
[4]Ahmed, N. et al. 1974. Discrete Cosine Transform. IEEE Transactions on Computers. 23, 1 (1974), 90–93.